Introduction to Flink
Table of Contents
What is flink?
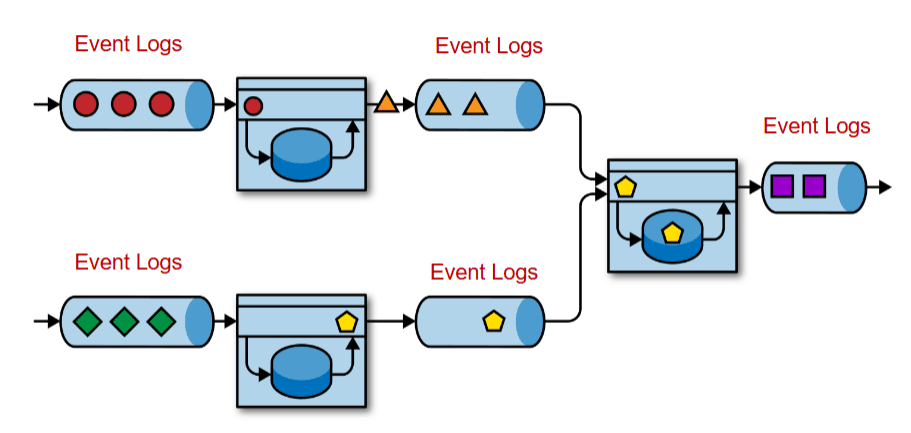
Flink is an event-driven streaming processor, which can be used to process real time streaming data. The input data can be from an event log/message queue such as Kafka, and the output would also be an event log. This design effectively decouples the sender and receiver, where the receiver can take their time to consume the message.
Example: Counting Hashtags with Apache Flink
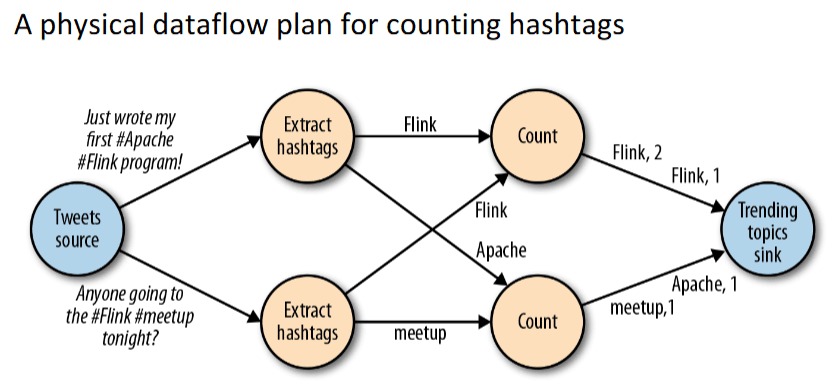
Let's look at a simple example of how Apache Flink can process streams of data in real time. Imagine a message queue containing tweets as our input source. These tweets flow into Flink's data pipeline, where the processing happens in multiple steps:
- Extracting Hashtags: For each tweet, we identify all the hashtags within it. These hashtags are essentially keywords prefixed by
#, like#Flinkor#Apache. - Counting Keywords: Once we extract the hashtags, the next step is to count how many times each unique keyword appears.
- Pushing Results: The results are sent to a trending topics sink, which consolidates all the counts and outputs the trending keywords along with their frequencies.
Flink divides this workload across its nodes, with each node handling a partition of the tweet stream. For example, in the diagram, one node processes tweets mentioning #Flink and #Apache, while another focuses on #meetup. At the trending topics sink, Flink combines these partial results to produce the final output — a list of hashtags and their respective counts, like #Flink: 2, #Apache: 1, and so on.
This approach demonstrates Flink’s capability to handle high-throughput data streams with low latency, making it a powerful choice for real-time analytics.
Flink's system architecture
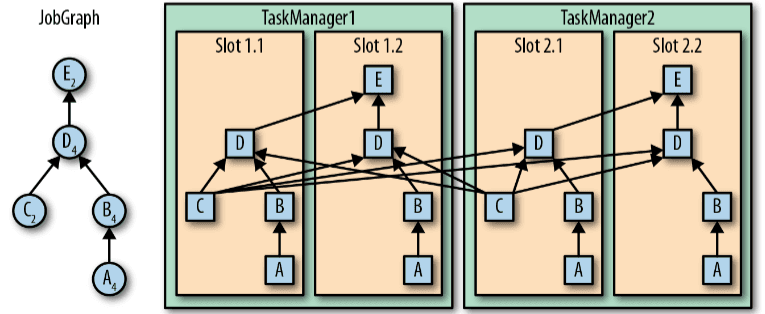
In Apache Flink's system architecture, users submit applications to the Job Manager (driver node), which acts as the central coordinator. The Job Manager communicates with the Resource Manager (cluster manager), responsible for managing and allocating resources within the cluster. The Resource Manager provides the Job Manager with resources to execute the submitted job.
Task Managers, which are worker nodes in the cluster, manage a predefined number of slots. These slots are offered to the Job Manager, which assigns tasks based on the job's dataflow graph. Once assigned, the Task Managers execute the tasks in parallel, ensuring efficient resource utilization and high scalability for stream processing.
How does Flink know when to trigger an event-time window?
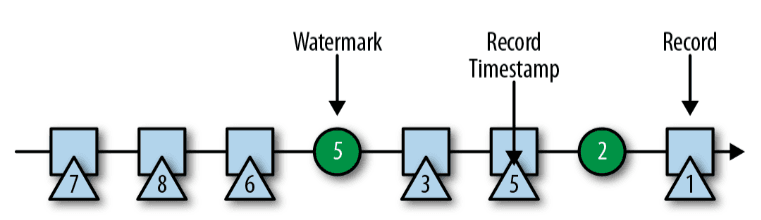
While Spark operates on the concept of microbatches—allowing us to trigger the result table at the end of each microbatch—Flink processes data as an event log. This raises the question: when should we trigger the results? Flink addresses this using watermarks, which act as signals for event-time window processing. Watermarks are injected into the streaming data by the user and represent the user's best estimate that all events with timestamps earlier than the watermark have already been processed.
Checkpointing in Flink
In Flink, a Task Manager process can fail unexpectedly at any time. To ensure fault tolerance, Flink periodically checkpoints the state of tasks to remote, persistent storage. This is achieved using a special type of record called a checkpoint barrier. These barriers are injected into the data stream by source operators and flow through the streaming topology. When a checkpoint barrier reaches an operator, it triggers the operator to persist its current state, ensuring that the system can recover seamlessly from failures.
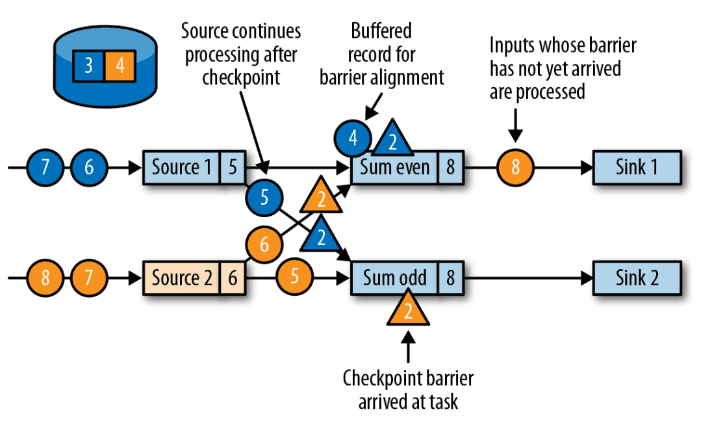
Since Flink's input sources are event logs, each source operator maintains a local state to track the offset or sequence number of events it has read. When a checkpoint barrier arrives at a source, the source checkpoints its current offset and forwards the barrier to the downstream operators. In the example above, the sum_even operator receives checkpoint barrier 2 from Source 1 . While it continues processing events like `4` from Source 1 , it buffers these records until checkpoint barrier 2 is also received fromSource 2 . Only after both barriers arrive and the checkpoint is completed does it resume processing the buffered events. Similarly, the sum_oddoperator waits for checkpoint barrier 2 from both sources before checkpointing its state and forwarding the barriers to Sink 1 and Sink 2. This ensures consistent state across all operators in the pipeline.